java爬虫,java如何爬虫
1、学习网络编程Socket 官方论坛java爬虫,可交流具体技术问题 四教程选择建议新手入门。
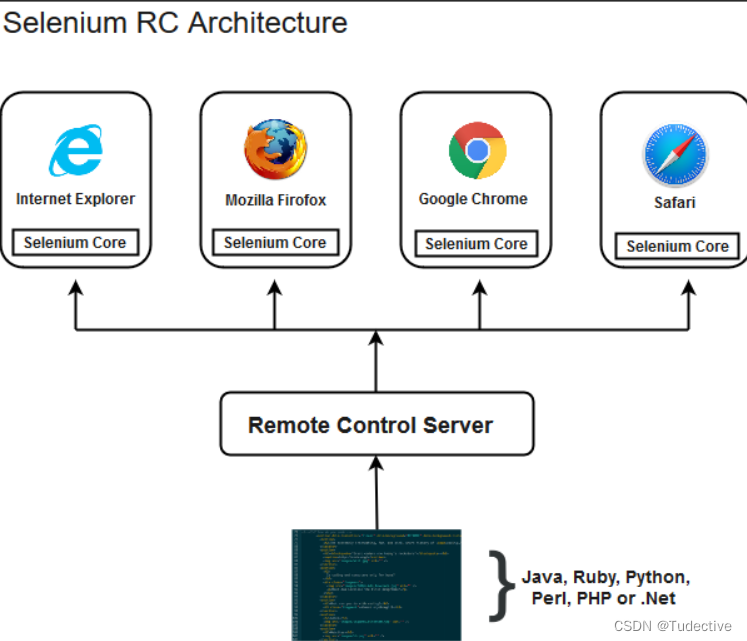
2、选择Java爬虫库 Jsoup适合静态HTML解析,支持DOM遍历和CSS选择器HtmlUnit模拟浏览器行为,可处理JavaScript渲染的页面Selenium自动化测试工具,适合复杂动态页面需配合WebDriver。
3、Java爬虫与Python爬虫的主要区别体现在语法和易用性性能和效率并发和分布式反爬虫机制以及应用场景等方面1 语法和易用性Python语法简洁清晰,易读易懂,对初学者友好,且拥有丰富的爬虫库,如BeautifulSoupScrapy和requests等Java语法较为严谨,可用的爬虫库相对较少,常用的有Jsoup等,需要较。

4、初学者的建议对于初学者来说,如果主要目的是快速入门并掌握爬虫技术,Python是一个更好的选择它不仅能够让你更快地编写出功能完善的爬虫程序,还能够让你在学习过程中享受到编程的乐趣当然,如果你对Java有浓厚的兴趣或者已经有一定的Java基础,选择Java学习爬虫也是可行的图片展示综上所述,Pyt。
5、使用Java程序爬虫实现阿里巴巴登录功能,需通过模拟表单提交获取响应并验证登录结果来完成以下是具体实现步骤及注意事项实现步骤获取登录页面URL并建立连接通过URL和URLConnection访问阿里巴巴登录页面,为后续表单提交做准备URL loginUrl = new URL#34#34URLConnection。
6、Java爬虫登录需要认证的网页,需通过获取表单信息模拟提交处理响应及会话保持等步骤实现,核心流程如下一获取登录表单信息解析HTML结构使用HTML解析库如Jsoup提取表单的action属性提交URL输入字段名称如usernamepassword及隐藏字段如CSRF令牌示例代码JsoupDocument doc = Jsoup。
7、Java爬虫能够执行以下主要任务数据抓取从各类网站新闻网站论坛博客等抓取信息,涵盖文本图片视频等多种数据类型网页索引为搜索引擎创建索引,将网页内容整理成易于检索的格式,从而提高搜索效率和质量信息提取从抓取的网页中精确提取特定信息,例如商品价格用户评论联系方式等,为。
8、开发网络爬虫时,选择合适的框架非常重要常见的爬虫框架可以大致分为三类1 分布式爬虫,如Nutch,主要解决大规模URL管理和高速网络爬取的问题2 Java单机爬虫,包括Crawler4jWebMagicWebCollector等,适用于单机环境下的爬虫开发3 非Java单机爬虫,如scrapy,适用于非Java环境下的爬虫开发分布。
9、本文对较为知名及常见的开源爬虫软件进行梳理,按开发语言进行汇总以下是部分Java爬虫1 Arachnid一个基于Java的web spider框架,包含一个小型HTML解析器通过实现Arachnid的子类开发简单的Web spiders,并在解析网页后增加自定义逻辑下载包中包含两个spider应用程序例子特点微型爬虫框架。
10、Python相对Java的优点 简洁易学的语法 Python的语法简洁清晰,使得初学者能够更快地上手,并将精力集中在编程对象和思维方法上,而无需过多关注语法细节相比之下,Java的语法较为繁琐,需要编写更多的代码来实现相同的功能强大的爬虫架构支持 Python拥有一些专为爬虫设计的强大架构,如Scrapy等,这些架构。
11、以下是部分知名的开源爬虫软件工具的简要介绍Java爬虫 Arachnid一个微型爬虫框架,含有一个小型HTML解析器,通过实现子类可开发简单的Web spiders许可证为GPL crawlzilla基于nutch专案的自由软件,安装简易,拥有中文分词功能,提供安装与管理UI授权协议为Apache License 2 ExCrawler由守护进程。
12、传统爬虫从一个或若干初始网页的URL开始,获得初始网页上的URL,在抓取网页的过程中,不断从当前页面上抽取新的URL放入队列,直到满足系统的一定停止条件对于垂直搜索来说,聚焦爬虫,即有针对性地爬取特定主题网页的爬虫,更为适合以下是一个使用java实现的简单爬虫核心代码public void crawl。
13、Python拥有更多爬虫相关的库Python社区为爬虫开发提供java爬虫了丰富的库和框架,如BeautifulSoupScrapylxml等,这些库和框架大大简化java爬虫了爬虫的开发过程相比之下,Java虽然也有相应的库,但数量和功能性上不如Python丰富易于集成与扩展Python的库和框架通常具有良好的集成性和扩展性,使得开发者可以轻松地。
14、缺点需要控制并发,并且要控制什么时候销毁线程thread1空闲,并且queue为空不代表任务可以结束,可能thread2结果还没返回,当被抓取的网站响应较慢时,会拖慢整个爬虫进度三实现 抓取方式最终还是选择了方法二,因为线程数可配置使用技术jfinal用了之后才发现这东西不适合,但是由于项目进度问题。
15、以下是33款可用来抓数据的开源爬虫软件工具Java爬虫 Arachnid基于Java的Web spider框架,包含HTML解析器 crawlzilla自由软件,支持建立搜索引擎,支持多种文件格式分析,中文分词提高搜索精准度 ExCrawler采用数据库存储网页信息的Java网页爬虫 Heritrix具有良好的可扩展性的Java开源网络爬虫。
16、使用Java写爬虫,常见的网页解析和提取方法有两种利用开源Jar包Jsoup和正则一般来说,Jsoup就可以解决问题,极少出现Jsoup不能解析和提取的情况Jsoup强大功能,使得解析和提取异常简单知乎爬虫采用的就是Jsoup6正则匹配与提取爬虫主要技术点5虽然知乎爬虫采用Jsoup来进行网页解析,但是仍然封装。