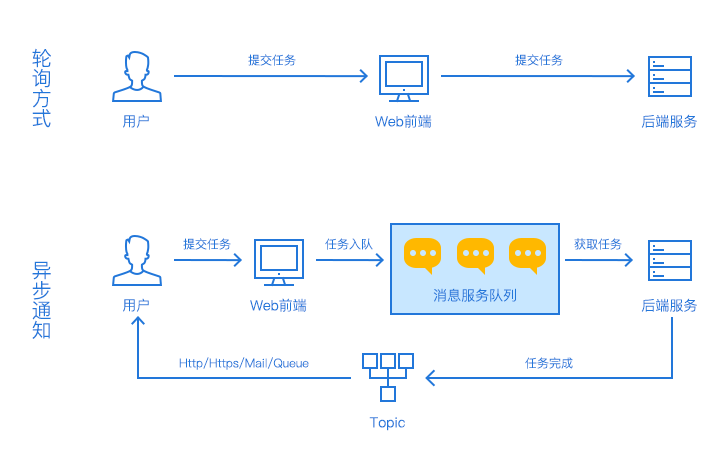
消息队列实现及相关应用与搭建步骤
请求缓冲:用户请求先写入队列,系统按处理能力从队列中消费请求,避免直接冲击后端服务。流量控制:若队列长度超过阈值,直接拒绝多余请求或引导用户至错误页面,保障系统稳定性。日志处理场景说明:大规模日志传输场景如Kafka的应用,通过消息队列实现高效日志收集与处理,日志采集客户端定时采集日志。
阿里云消息队列Kafka的检索组件通过将消息数据转存至表格存储Tablestore并构建多元索引,实现了对消息内容的灵活检索,有效解决了消息丢失、重复消费等场景下的排查难题。以下是具体实践与能力扩展的详细说明:一、消息检索组件核心功能技术架构,通过Kafka Connector将Topic中的消息实时转存至。

在Linux系统上实现Kafka消息队列,需按以下步骤完成环境搭建与基础操作:一、安装Java运行环境,Kafka依赖Java,推荐使用OpenJDK 11或Oracle JDK 11。以OpenJDK 11为例,sudo apt update,sudo apt install openjdk-11-jdk,验证安装:java -version,输出应显示OpenJDK 11版本信息。二、下载并解压Kafka从Apache。
在Java 18环境中,最简单好用的消息队列取决于具体需求和场景,但基于常见情况,可以考虑使用Java的并发包实现内存中的消息队列,或者利用Redis实现轻量级消息队列。一、使用Java并发包实现内存中的消息队列,方法简介:这种方法不需要引入外部依赖,非常适合学习和理解消息队列的基本原理。